关键字
容灾、无感知切换、统一界面管理、态势感知
容灾、无感知切换、统一界面管理、态势感知
集成平台容灾重要性与日俱增,“靠人盯”和“堆人修”令人烦恼
随着集成平台在医院业务中的核心地位不断巩固,其容灾的重要性也日益突显。 传统的热备、双活等架构需要运维人员不断关注,有时甚至需要在半夜被叫醒去解决问题。
然而,这种“靠人盯”的方式存在缺陷,只有在出现异常并被人感知后才能得到响应,小问题的恢复时间(RTO)通常需要数分钟,而问题更严重时,恢复时间可能会达到数小时,严重影响日常业务甚至可能引发医疗事故。 此外,运维人员在解决问题的过程中需要不断协调多个系统和厂商,令他们疲于奔命。 这也导致医院需要“堆人”,花费大量时间和精力来应对容灾问题。 解决这些问题的一种有效方式是使用 Odin引擎AO版,但更好的选择是使用Odin引擎一体化集群版。
Odin引擎一体化集群版如何解决上述问题
无感知切换自主容灾,解决“靠人盯”的问题
Odin引擎一体化集群版通过多个Worker节点采用Masterless的组网方式
实现分布 式架构,这种方式通过多个节点之间的状态和配置同步来保证系统的容灾和高可用能力。 当其中一个节点失效时,其他节点可以自动接管其任务,辅以Odin具备的无感知切换、异常通知和自修复等功能,即使无人值守也能自主容灾,实现无感知切换。 这解决了“靠人盯”的问题, 医院日常运行不会受到任何影响,整个系统的高可用性得到保障 。
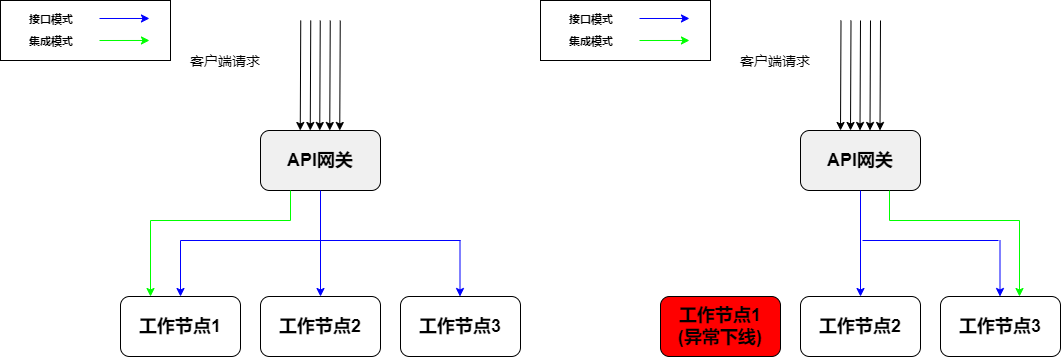
Odin集群架构容灾切换示意图
统一界面管理快速定位,解决了“堆人修”的问题
一体化指的是包括开发、运维、监控等在界面、组件以及管理上的统一化,并且在集群环境下各工作实例能够互为感知,对外形成逻辑一体的运算系统。 这种方式能更好地监控和配置计算资源,提升整体能效,同时能够大幅降低运维难度,避免管理疏漏。
Odin 引擎一体化集群版具备独特的统一界面管理能力,当出现异常或故障时,运维人员能 通过统一的界面对于工作实例运行状态以及其中各业务情况进行浏览查看 ,避免了对服务器一一排查或频繁切换服务器管理界面的繁琐操作,快速定位问题,大幅降低了异常发生时集成平台容灾恢复的时间和工作量,这是多台服务器二次开发后搭建的 “集群”所难以具备的能力,从而解决了“堆人修”的问题。
其它应对“靠人盯”和“堆人修”问题的功能——全局态势感知
除了上述两点,Odin还提供了众多功能应对“靠人盯”和“堆人修”的问题,其中就包括了全局态势感知。 全局态势感知能提供预警功能,提前感知可能存在或将会发生的风险,让运维人员不用成为“救火队员”,有效地减少系统故障造成的影响,提高整个系统的稳定性和可用性。
结语
随着集成平台容灾的重要性日益突显,传统架构已经很难满足集成平台的容灾需求。 Odin一体化集群架构的无感知切换,统一界面管理和态势感知等功能,能够帮助运维人员更快速、更精准地发现和解决问题,告别“靠人盯”和“堆人修”的集成平台容灾运维方式。

Odin文章评论: