关键字
内存过载如何预防、熔断机制配置流程、如何保证引擎稳定运行
内存过载如何预防、熔断机制配置流程、如何保证引擎稳定运行
场景分析
集成平台中间件(例如集成引擎、ESB)独立运行在服务器环境中时,CPU和内存资源相对固定,当处于运行状态时,集成平台中间件上的各数据项目均会根据自己的配置对这些资源进行使用。 有很多业务场景下,会有对数据表进行查询,然后对查询数据进行转换和处理等场景,比如: “两个数据库表之间的同步”,“批量获取患者病案信息”,“每日费用结算”等。 这时候如果一次查询的数据比较大,恰好集成平台中间件上运行的业务比较多,内存使用已在高位的情况下,在某一时刻很可能会出现内存过载导致引擎异常甚至是服务器宕机的状况。
问题分析
出现这种情况一般是因为配置时对SQL查询语句未做充分测试或者未考虑到真实环境下查询量导致,这在任务紧、压力大的医院集成项目中经常会遇到,一旦出现这种情况,很可能会造成引擎、服务器假死或者不稳定。
Odin引擎的对策
在同某家医院进行技术交流中,合作厂商提到他们有遇到过类似问题。 Odin在意识到此问题的重要性后,2周内引入内存过载保护熔断机制,并及时发布升级通告,避免项目中可能因为此类问题导致的服务器不稳定的问题,从根本上预防此类问题的发生。
内存过载保护熔断机制,顾名思义,就是通过设定阈值限制一次性读取数据的大小,若读取的数据量超过阈值上限,则会出现错误提醒并自动触发熔断机制,防止内存过载的情况发生,保证服务器的稳定运行。
Odin引擎的内存保护熔断机制配置
运维人员可以通过Odin引擎的“数据库终端配置”界面直接进行该功能的配置,初始默认阈值为16MB,表示可一次性读取数据所占用的内存上限为16MB,医院可以根据实际操作情况对该值进行修改合理地调整数据读取上限。 若确实存在某些大文件需要被一次性读取,也可以手动修改读取的数据大小上限,在结束读写后将读取上限再改回原值。
具体配置流程分为两步:
1. 估算内存
数据库里表的大小并不是代表消息运行时占用的内存大小以及对应的JSON或者XML数据的大小,因此需要合理地根据消息数量和数据表大小估算查询时占用的内存资源。 可以通过数据库终端写查询脚本测试进行估算,通过不断增加一次性读取的数据的行数,判断报错时大约的数据记录数(例如一次读取6000行数据没有问题,但是当一次读取6500行数据时就显示出错了,那6000行数据就可以预估为该环境和配置下的数据量读取上限,当然测试的次数越多综合得出的结果越具有参考价值)。
那对应的内存上限一次能读取多少数据?
假设数据表中的一行信息为10个字段VARCHAR(200),每个字段内填写10个汉字,则每个字段大约20 bytes,10个字段共200 bytes (即在数据库中一行数据的大小约为200 bytes) ,在这种前提下:
其他数据库也可根据此方式进行测试,以便找出合理的阈值。
由于每个业务表和数据库均会影响到数据量大小和内存占用,项目开发人员和运维人员可以根据日常调用数据量大小逆向估算出单次数据读取可能占用的内存资源,并以此为标准确定触发熔断机制的内存上限。
2. 设置数值
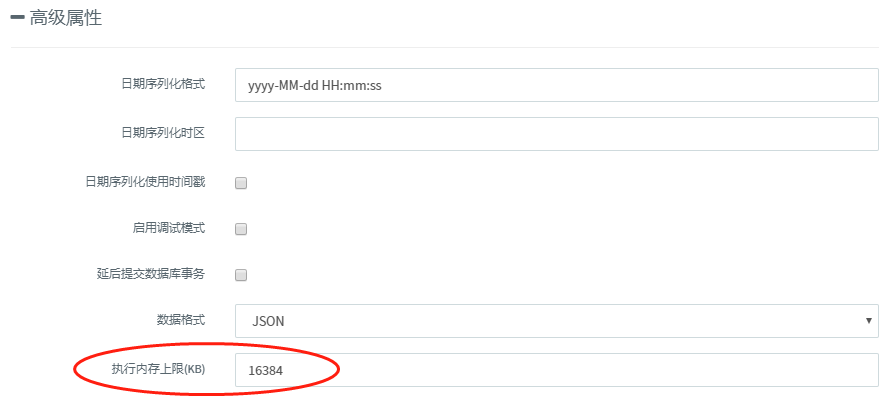
通过合理地配置,设置红圈内的“执行内存上限”数值,Odin引擎的内存过载保护熔断机制能保证医院运维人员日常的数据读写操作,同时极大程度地杜绝了因误操作一次性读取大量数据导致的内存过载问题的发生。
以上是关于Odin引擎内存过载保护熔断机制的介绍,未来还会有更多Odin引擎的精细化技术和功能的解析,敬请关注!

Odin文章评论: